Переводческая инженерия
Инженерно-конструкторский козел в оГороде Переводчиков
Сравнительный анализ объемов текста оригинала и перевода научно-технических документов |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Наверняка, подобный анализ в переводческой науке или практике (переводоведении) уже когда-то кто-то проводил. Речь идет об исследовании соотношений количества знаков (с пробелами и/или без таковых) и слов в текстах оригинальных документов и их переводов для различных языковых пар и различных типов переводимых материалов. Действительно, различие в количестве знаков оригинального (например, английского) текста и его перевода (например, на русский или украинский) бросается в глаза, но мне не удалось пока найти обоснованных статистических данных, количественно и с разных сторон отражающих такое различие. Данный вопрос интересен не только с теоретико-познавательной точки зрения исторических лингвистических трансформаций единого праязыка рассматриваемой языковой пары, но имеет и чисто практическое значение, например, при планировании типографских площадей для публикации переводных материалов или при необходимости предварительного расчета стоимости их перевода. Что за проблема?Понятно, что результат труда переводчика может быть измерен лишь по завершении работы, то есть по переведенному тексту. Однако для заказчика, да и для самого переводчика, часто желательно заранее представлять себе объем переводческой работы или даже необходимо обоснованно подсчитать стоимость перевода. Проблема нормирования такого расчета в целом определена в моей статье «Проблемы нормирования расчета гонораров за перевод» (см. ). А здесь рассмотрим один из возможных подходов к ее решению. Для предварительного определения объема перевода на русский язык в условно-стандартных страницах по иностранному оригиналу официальные Рекомендации (см. http://www.translators-union.ru/community/recommendation/) предлагают применять установленные эмпирическим путем пересчетные коэффициенты, приведенные в таблице 1 для разных языков текста оригинала (см. http://www.akmw.ru/info-price.html). Таблица 1. Пересчетные коэффициенты для определения объема текста перевода на русский язык
А подсчет слов в тексте перевода рекомендуется выполнять в редакторе Word или Power Point с последующим умножением количества слов на число 9 — эмпирически выведенное среднее количество символов в русском слове с учетом одного пробела после него. И делается оговорка: «Для других языков (или для других (каких? — С.П.) текстов) это количество будет, конечно, различным».
В упомянутом документе отсутствуют ссылки на то, кто, как и когда выполнял такие эмпирические исследования и делал из них выводы. Каких-либо других ссылок по рассматриваемому вопросу я в Интернете также не обнаружил. Между тем, вопросов по упомянутой рекомендации относительно пересчета объема оригинала в объем перевода довольно много. Например:
· Какой объем текста на условно-стандартных страницах имеется в виду — с учетом или без учета пробелов. · Точность указанных в таблице 1 коэффициентов недостаточна (я вообще не представляю, зачем указаны нули во втором дробном разряде?!) — при больших объемах текста ошибка (разброс) может составить весьма приличную сумму, что очень может быть небезразлично как заказчику, так и переводчику. · Обоснованность данных — какие рассматривались тексты (тематика, наличие таблично-иллюстративного материала), объем выборки и т. п. · Отсутствуют показатели среднеквадратического отклонения, позволяющие обосновать степень точности соответствующих вычислений и так или иначе учесть возможные «риски», которыми сопровождается заключение контракта на переводческую работу.
Ответ на каждый из этих вопросов будет в большей или меньшей степени влиять на результаты расчетов. Однако, нам с вами для денежных подсчетов очень хотелось бы использовать вполне обоснованные данные. Тем более достоверных эмпирических данных требует разработка унифицированной системы исчисления гонораров за перевод. В такой ситуации естественным представляется проведение собственных исследований в полном соответствии с требованиями, которые предъявляются к любым статистическим исследованиям объективной реальности.
Итак, поехали…
На рисунках 1 и 2 приведены результаты статистических исследований величин средних арифметических значений и стандартных отклонений указанных коэффициентов, вычисленные на основе пробной выборки из n = 42 пар текстов научно-технической, юридической и т. п. тематик выполненных мною переводов (которые можно считать «репрезентативными» в том смысле, что они одобрены и приняты заказчиками). Когда я рассматривал тексты переведенных мною книг, в это исследование я включал их отдельные главы с тем, чтобы избежать слишком больших объемов отдельных документов: в любом случае будут получаться лишь среднестатистические величины изучаемых параметров текстов. В дальнейшем для расширения области исследований можно рассмотреть тексты других переводчиков с разными уровнями, так сказать, переводческого и писательского мастерства.
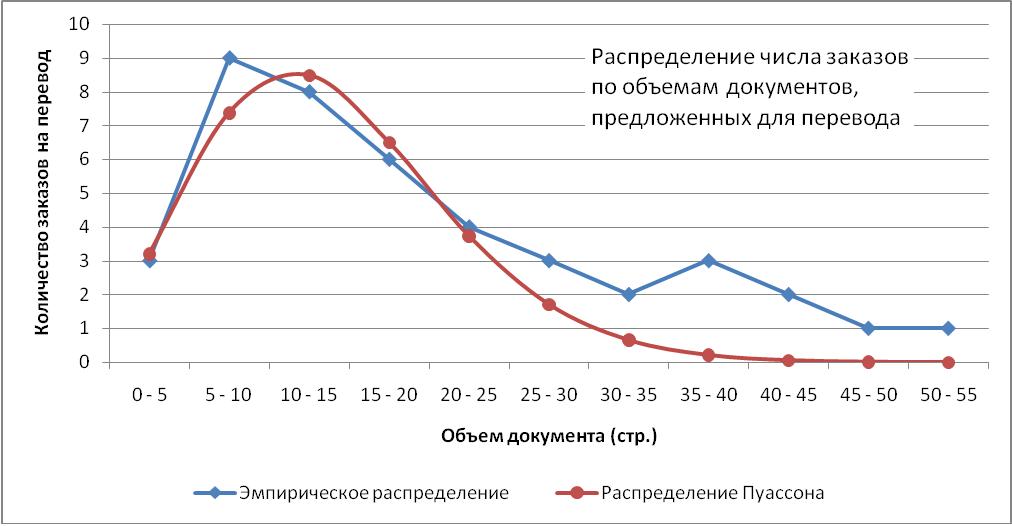
Документы какого объема мы переводим? Относительный объем текстов оригинала в страницах характеризует средний объем единичных документов, с которыми приходится иметь дело переводчику. На рис. 1 синей линией представлено распределение числа заказов по объемам документов, предложенных мне для перевода. Как видите, чаще всего на перевод поступали документы объемом от 10 до 15 страниц, и хотя более объемные документы тоже встречаются, но с ростом их объема они попадаются все реже и реже. Рисунок 1 Обращает на себя внимание сходство показанного графика с распределением Пуассона, описывающим так называемый закон распределения редких явлений. Каждый переводчик-фрилансер согласится с тем, что получить заказ (любого объема!) на перевод — действительно редкое явление! Тем не менее, если вы давно работаете в режиме свободного художника (читай — переводчика), то вероятность получить работу объемом, попадающим в диапазон m (m — номер диапазона объемов документа на рис. 1), можно описать аналитической формулой
Рm = am e-a / m!,
где параметр распределения Пуассона а характеризует интенсивность у вас появления заказов или, что то же, вашу популярность у заказчиков. У меня этот параметр оказывается равным примерно а = 2,3; этому значению а соответствует распределение Пуассона, показанное на рис. 1 коричневой линией. Тот факт, что, начиная с объемов документов 25 – 30 страниц, синяя и коричневая кривые расходятся, свидетельствует о том, что получение заказов на перевод сравнительно объемных документов — событие для меня не такое уж и редкое!
Относительные объемы текстов оригинала и перевода Идем дальше. В наши расчеты будут входить коэффициенты, имеющие конкретные числовые значения для конкретных языков текстов оригинала/перевода. К таким коэффициентам, в первую очередь, относится среднеарифметическое количество знаков в одном слове для текстов на разных языках — английском и русском (украинском), а также безразмерные параметры, характеризующие разницу морфо-лексемных объемов текстов оригинала и перевода:
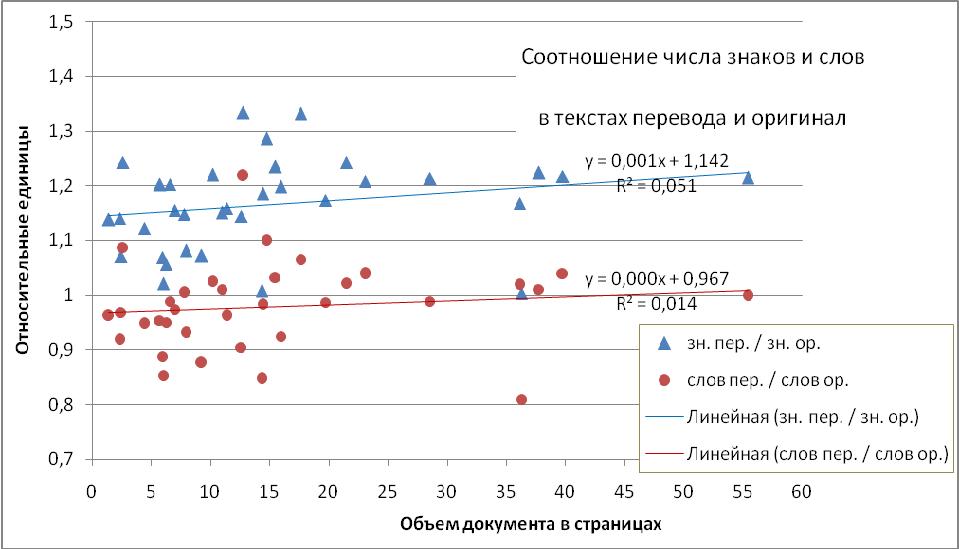
На рис. 2 точками изображены величины отношений числа знаков и слов оригинала и перевода для отдельных текстов, с которыми я работал, в зависимости от их страничного объема sw (напомню, что здесь 1 стр. = 2000 зн. с пробелами). На графиках также показаны линейные аппроксимации линий тренда обеих зависимостей, из которых следует, что в целом среднее количество знаков в слове как оригинала, так и перевода в определенной степени варьирует с увеличением объема их текстов. Я не знаю, чем это можно было бы объяснить, но тот факт, что рассматриваемые величины и для малых объемов испытывают значительные флуктуации, говорит о принципиальном отсутствии зависимости nsw(sw). Рисунок 2 Приведенные в таблице 2 среднеарифметические величины коэффициентов перехода ksto и kwto вычислены для случая направления перевода английский ⇒ русский, то есть когда английский текст является оригиналом (or), а русский — переводом (tr). Очевидно, для случая перевода русский ⇒ английский будут иметь место обратные величины коэффициентов ksto и kwto.
Таблица 2
В таблице 3 представлены количества слов оригинала и перевода на условных страницах объемом 1800 и 2000 знаков, часто используемые переводчиками для расчетов своих гонораров.
Таблица 3
Обратите внимание на такой неочевидный факт: количество английских слов на странице объемом 1800 знаков больше, чем русских слов на странице 2000 знаков.
От чего может зависеть разница объемов текстов оригинала и перевода Итак, знаковый объем текста русского/украинского перевода по сравнению с английским оригиналом увеличивается. Такое увеличение обусловлено не только тем, что множество слов в русском или украинском языках значительно «длиннее» своих английских аналогов, но и является результатом грамматических, лексических и стилистических трансформаций оригинального текста, которые часто требуют не только замены, но и ввода дополнительных слов (лексем). Вообще, отыскание взаимно-относительных статистических величин морфо-лексемных объемов текстов английского (и не только) оригинала и его перевода представляет собой отдельную очень интересную научную задачу. Слов в переводе оказывается, как правило, меньше, чем в оригинале. Хотя в результате решения различных переводческих ситуаций количество «существенных» слов в переводе, как правило, увеличивается, общее снижение их числа обусловливается естественным удалением из перевода множества артиклей, используемых в оригинале. Этот факт будет для нас существенным, когда ставки предлагаемых гонораров будут исчисляться относительно слова (слов) оригинала и/или перевода. Вполне может иметь место зависимость среднего количества знаков в слове от типа текста, характеризуемого его предметной областью:
а также от относительного объема в нем таблично-цифровых данных. Однако, исследованные мною тексты я особенно не классифицировал по указанным типам, и, скорее всего, именно поэтому получил столь «колебательные» результаты. Посему для расчетов нужно использовать только среднеарифметические величины рассматриваемых показателей, а также, возможно, их стандартные отклонения — в целях взаимного уменьшения «рисков» для заказчиков/переводчиков при предварительном (до осуществления перевода) оформлении контрактов. И, конечно, очень желательно существенно расширить выборку анализируемых текстов. Есть теория насчет того, сколько тысяч текстов нужно изучить, чтобы иметь репрезентативный результат заданной обеспеченности. После того как для оценки интересующих нас параметров генеральной совокупности пар текстов обоснованно выбран способ формирования (образования) выборки, рассчитываем минимально необходимый объем N выборки, задавшись желаемой степенью точности оценки ∆ = ±0,2 (= ±20%) и доверительной вероятностью р = 1 – α = 0,999. При этом предполагаем, что случайные величины nsw,or(tr) подчиняются нормальному закону распределения. Формула для расчета требуемого объема выборки пар текстов для нашего исследования имеет вид:
N = t2n,p * s2 / ∆2, где
Подставляя указанные значения параметров в нашу формулу, для nsw,or (см. также таблицу 1) получим:
N = 3,659^2*0,401549^2/0,2^2 = 53,968696 ≈ 54 пары текстов.
Конечно, если мы захотим повысить точность оценивания nsw,or до, скажем, ∆ = ±0,05 (= ±5%), то необходимый объем выборки существенно увеличится:
N = 3,659^2*0,401549^2/0,05^2 = 863,499137 ≈ 864 пары текстов.
Набрать такое количество экспериментального материала (образцов пар текстов), в принципе, несложно, но — нужно ли это?
РезюмеИтак, уважаемый читатель, найденные эмпирические среднестатистические величины знаковых и словных объемов различных английских текстов и их переводов позволяют обоснованно определить размер некой условной страницы текста оригинала и/или перевода, на основе которой можно будет так же обоснованно назначать и выбирать наиболее оптимальные ставки гонораров, выплачиваемых переводчикам за их труд. Именно об этом я пишу в своей следующей статье.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||